ETL vs ELT Comparison
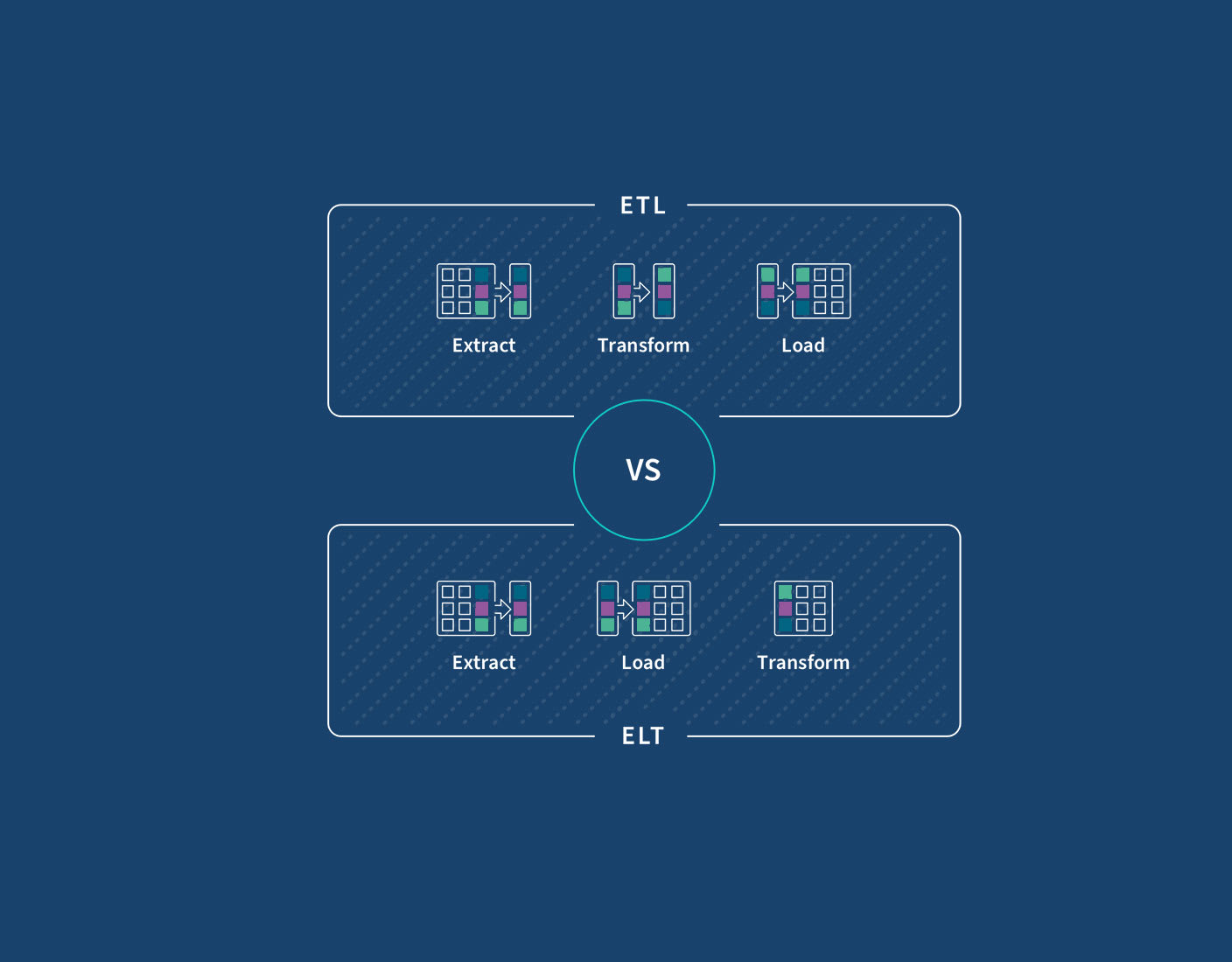
The letters stand for Extract, Transform, and Load
Extract refers to the process of pulling data from a source such as an SQL or NoSQL database, an XML file or a cloud platform.
Transform refers to the process of converting the format or structure of a data set to match that of a target system.
Load refers to the process of placing a data set into a target system.
The difference between ETL and ELT is when data transformation happens.
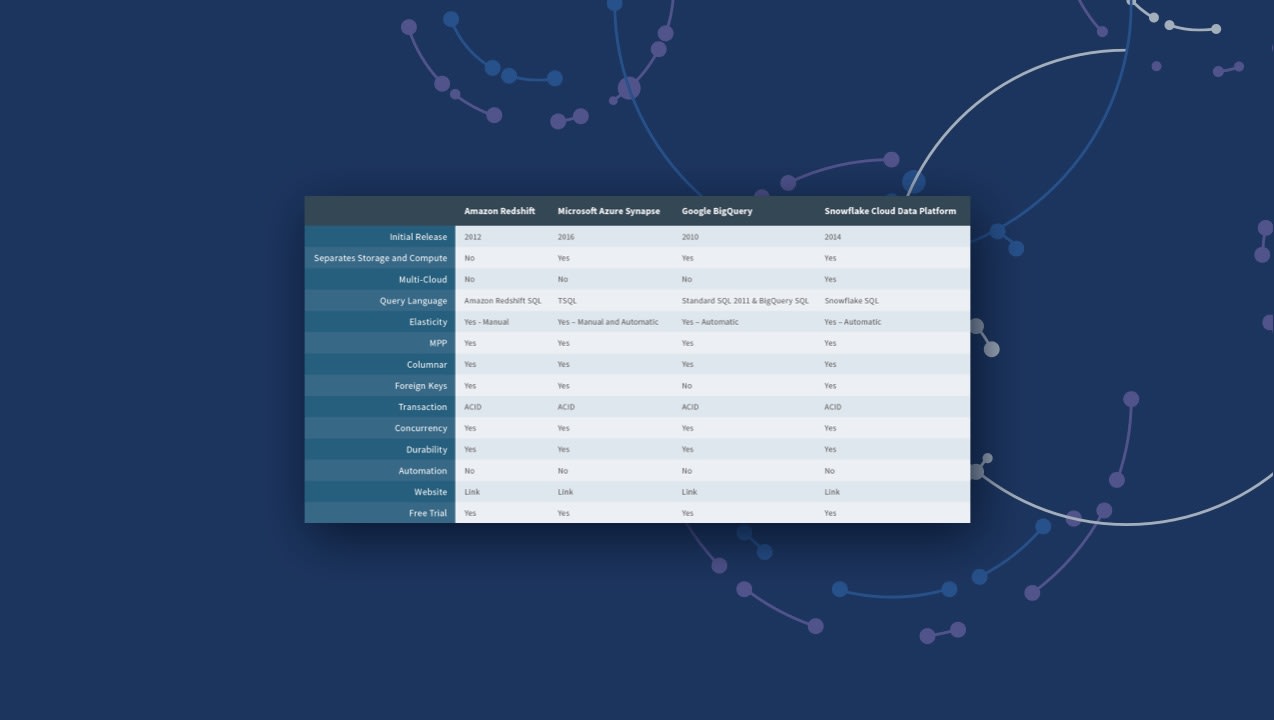
Here is a side-by-side comparison of the two processes:
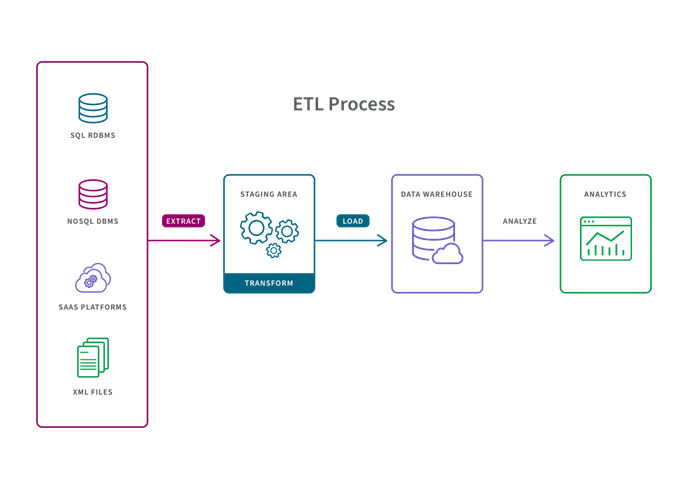
ETL stands for Extract > Transform > Load
In the ETL process, data transformation is performed in a staging area outside of the data warehouse and the entire data must be transformed before loading. As a result, transforming larger data sets can take a long time up front but analysis can take place immediately once the ETL process is complete.

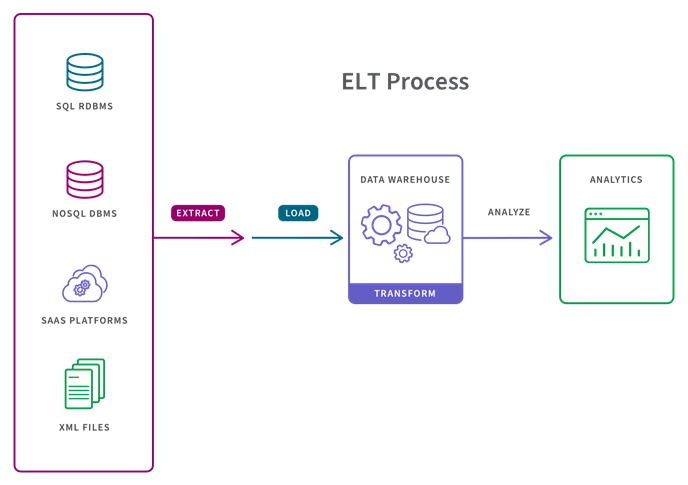
ELT stands for Extract > Load > Transform
In the ELT process, data transformation is performed on an as-needed basis in the target system itself. As a result, the transformation step takes little time but can slow down the querying and analysis processes if there is not sufficient processing power in the cloud solution.
There is a place for each process.
The ETL process is appropriate for small data sets which require complex transformations. The ELT process is more appropriate for larger data sets and when timeliness is important.