Talendのジョブ設計パターンとベストプラクティス(第1部)
Talend開発者が、経験が浅かろうが豊富であろうが共通して直面することが多いのが、「このジョブを記述する最善の方法は何か」という疑問です。 効率的で、読みやすく、記述しやすく、何よりも(ほとんどの場合)維持しやすいものであるべきなのは当然です。 また、Talend Studioという自由形式の「キャンバス」では、コンポーネント、リポジトリーオブジェクト、メタデータ、及びリンケージオプションの包括的で多彩なパレットを使用してコードを「描画」できることもわかります。 では、ベストプラクティスを使用してジョブ設計を作成したことを、どのように確認したらよいのでしょうか。
ジョブ設計パターン
Talendを使い始めたバージョン3.4以降、ジョブ設計は私にとって非常に重要でした。 最初は、ジョブの開発でパターンを考慮することはありませんでした。それ以前からMicrosoft SSIS等のツールを使用していたので、Talendのようなビジュアルエディターには馴染んでいました。 パターンに焦点を当てる代わりに、基本的な機能、コードの再利用性、次にキャンバスのレイアウト、そして最後に命名規則に注目していました。 しかし、さまざまなユースケース向けに数百のTalendジョブを開発し、コードがより洗練されて再利用性や一貫性も向上したことから、一定のパターンが浮かび上がってきました。
今年1月にTalendに入社して以来、顧客が開発したジョブを目にする機会に多く恵まれました。その結果、全ての開発者にとって、それぞれのユースケースに複数のソリューションがあるという認識に確信を持ちました。 このことが、開発者の多くにとっての問題となっているようです。 私たち開発者は同じような考え方をしますが、自分のやり方が特定のジョブを開発するうえで最善であると思い込みがちです。一方で、さらに良い方法が存在する可能性に薄々気が付いてもいます。 そこで、ベストプラクティスが必要となり、この場合はジョブ設計パターンを探すことになります。
基本的指針の明確化
可能な限り最善のジョブコードを実現するために必要なことを考えるときには、常に基本的指針が適用されます。この指針は、長年にわたるミスと成功に基づく改善の積み重ねから生まれたものです。 これはコード構築の強固な基盤となり、(私見ですが)ないがしろにしてはならない重要な原則であり、次の事柄が含まれます(順序は問いません)。
- 読み取りやすさ:簡単に把握し、理解できるコードを作成する
- 記述しやすさ:最短期間に平易で単純なコードを作成する
- 維持性:変更の影響を最小限に抑えて適度な複雑さを組み込む
- 機能:要件を満たすコードを作成する
- 再利用性:共有可能なオブジェクトと小さな作業単位を作成する
- 整合性:チーム、プロジェクト、リポジトリー、コードにわたる実質的な規範を作成する
- 柔軟性:曲げることはできても折れることのないコードを作成する
- 拡張性:要求に応じてスループットを調整する弾力のあるモジュールを作成する
- 一貫性:全てにわたる共通性を作り出す
- 効率:最適化されたデータフローとコンポーネント利用を作り出す
- 区画化:単一の目的に対応する、焦点を絞った小さなモジュールを作成する
- 最適化:最小限のコードで最大限の機能を作り出す
- パフォーマンス:最速のスループットを生む効果的なモジュールを作成する
これらの指針全体で実質的なバランスをとることが重要です。特に最初の3項目は常に相反するため、調整が欠かせません。 2つの項目を満たして3つ目を犠牲してしまうことはよくあります。 できるだけ重要度に基づいて順序付けるようにします。
(基準ではなく)規範としてのガイドライン
実際にジョブ設計パターンの検討に入る前に、前述した基本的指針と併せて、考慮すべきいくつかの詳細事項について確認しておきましょう。 設定されている基準に想定外の状況に対処する余地がなく、融通が利かないために、支障が出ることがしばしばあります。 また逆に、基本的に同じことをしている複数の開発者が、弾力性がなく不合理で矛盾するコードを作成したり、さらには支離滅裂な計画されない無秩序状態を広げたりすることが頻繁に起こっています。 率直に言って、これはずさんで見当違いなことであり、容易に回避できます。
このため、まず「基準」ではなく「ガイドライン」を作成して文書化することをお勧めします。 ガイドラインは基本的指針を取り上げるものとし、それに具体的詳細を追加します。 「開発ガイドライン」文書が作成され、SDLC (ソフトウェア開発ライフサイクル)プロセスに関与する全てのチームによって採用されると、この基盤が構造、定義、及びコンテキストをサポートします。この基盤構築に取り組むことにより、長期的には誰もが満足する結果を得ることができます。
以下に提案する概要をご利用ください(あくまでもガイドラインなので、自由に変更/拡張できます)。
- 方法論:構築の「方法」を詳細に説明
- データのモデリング
- 全体的/概念的/論理的/物理的
- データベース、NoSQL、EDW、ファイル
- SDLCプロセスコントロール
- ウォーターフォールまたはアジャイル/スクラム
- 要件と仕様
- エラー処理と監査
- データガバナンスとスチュワードシップ
- データのモデリング
- テクノロジー:「ツール」(内部及び外部)とその相互関係を列挙
- OSとインフラストラクチャのトポロジ
- DB管理システム
- NoSQLシステム
- 暗号化と圧縮
- サードパーティソフトウェアの統合
- Webサービスのインターフェイス
- 外部システムのインターフェイス
- ベストプラクティス:「何」が「どんなとき」にガイドラインに従う必要があるかを説明
- 環境(DEV/QA/UAT/PROD)
- 命名規則
- プロジェクト、ジョブ、及びジョブレット
- リポジトリーオブジェクト
- ログ管理、監視、及び通知
- ジョブのリターンコード
- コード(Java)のルーチン
- コンテキストグループとグローバル変数
- データベースとNoSQLの接続
- ソース/ターゲットデータとファイルのスキーマ
- ジョブのエントリ-/終了ポイント
- ジョブのワークフォローとレイアウト
- コンポーネントの利用
- 並列化
- データ品質
- 親/子ジョブとジョブレット
- データ交換プロトコル
- 継続的な統合と展開
- 統合ソースコード管理(SVN/GIT)
- リリース管理とバージョン管理
- 自動テスト
- アーティファクトリポジトリーとプロモーション
- 管理と運用
- 構成
- ユーザーセキュリティと承認
- ロールと許可
- プロジェクト管理
- ジョブのタスク、スケジュール、トリガー
- アーカイブと災害復旧
さらに、以下のドキュメントを作成して維持すべきです。
- モジュールライブラリ:再利用可能な全てのプロジェクト、メソッド、オブジェクト、ジョブレット、コンテキストグループについて
- データディクショナリー:全てのデータスキーマと関連ストアドプロシージャーについて
- データアクセスレイヤー:データへの接続とデータの操作に関連する全てについて
このようなドキュメントの作成には時間がかかりますが、そのライフサイクル全体にわたってもたらされる価値はコストをはるかに上回ります。 簡素で直接的で最新のドキュメント(マニフェストである必要はありません)を保持することで、ドキュメントを使用する全てのプロジェクトで開発ミス(そのコストはより大きなものです)が大幅に減り、プロジェクトの成功に大きく役立ちます。
ジョブ設計について
ようやくジョブ設計について検討できる準備が整いましたが、 その前にもう1つ忘れてはならないことがあります。 どの開発者にも、コードの記述で良い習慣と悪い習慣の両方があります。したがって、良い習慣に基づくことが不可欠です。 全てのコンポーネントに常にラベルを付ける等、簡単な習慣から始めましょう。 これによって、コードが読みやすく理解しやすくなります(前述した基本的指針の1つです)。 全員がこの習慣を身に着けたら、全てのジョブにプロジェクトに合った有意義な名前を使用し、リポジトリーフォルダー内に慎重に整理していること(整合性)を確認してください。 次に、System.out.PrintLn()関数に一般的なメソッドラッパーを使用する等して、同じ形式のログメッセージを使用し、また、代替要件のオプションを含む、ジョブコードの共通のエントリー/終了ポイント基準を確立します(両方とも、いくつかの指針をまとめて実現するうえで役立ちます)。 明確に定義された開発ガイドラインの規範を開発チームが採用して活用していくにつれて、チーム全員にとってプロジェクトコードの読みやすさ、記述しやすさ、そして(私が特に重視する)維持性が向上します。
ジョブ設計パターンとベストプラクティス
Talendのジョブ設計パターンは、特定のユースケースに焦点を当てる基本/必須要素を含む、テンプレートやスケルトンのレイアウトを提示するものと考えることができます。 パターンは、類似するジョブ作成のためにしばしば再利用できるため、コード開発の開始に弾みがつきます。 ご想像のとおり、いくつかの異なるユースケースで採用可能な共通の使用パターンもあります。そのようなパターンを適切に識別して実装することで、コードベース全体を強化し、作業を凝縮し、反復的な類似するコードを削減できます。 したがって、ここから始めましょう。
考慮すべき7つのベストプラクティスについて、以下に説明します。
キャンバスのワークフローとレイアウト
ジョブキャンバスにコンポーネントを配置するには多くの方法があり、それらをリンクさせる方法も多くあります。 個人的には、基本的に「上から下へ」、次に「左から右へ」という方向で作業するとよいと考えます。左向きのフローは、一般的にエラーパスであり、右向きや下向きのフローが望ましい正常のパスとなります。 可能な限りリンク線の交差を避けることをお勧めします。バージョン6.0.1の時点では、適度にカーブしたリンク線を使用することが、この戦略に役立ちます。
「ジグザグ」パターンで、コンポーネントを「左から右へ」連続して配置し、一番右端の境界に到達すると次のコンポーネントがドロップされて左端に戻り、同じようなことが続く、というパターンは、個人的には扱いにくく維持が難しい場合があると思っていますが、その利点(記述しやすさ)も理解できます。 どうしても避けられない場合はこのパターンを使用してもよいでしょうが、ジョブが必要以上の機能を実行している可能性が示唆されたり、適切に整理されないことがあります。
小さなジョブモジュール 〜 親/子ジョブ
多くのコンポーネントを含む大規模なジョブは、端的に言って、理解して維持するのが難しいだけです。 大規模にならないように注意し、可能な限り常に小さなジョブや作業単位に分割してください。 その後、子ジョブとして、その制御と実行を目的に含む親ジョブから実行します(tRunJobコンポーネントを使用)。 これによって、エラーの処理と次に起こることへの対応を改善する機会も生まれます。 R整理されていないジョブは理解しにくく、デバッグ/修正が困難で、維持がほとんど不可能であることを忘れないでください。明確な目的を持った簡潔で小さなジョブは、キャンバスを見ただけで容易に意図を理解でき、また、必ずと言ってよいほどデバッグ/修正が簡単で、メンテナンスも比較的簡単です。
ネストされた親/子ジョブ階層を作成することも容認されますが、考慮しなければならない実際の制限事項があります。 ジョブメモリ使用率、渡されたパラメーター、テスト/デバッグの問題、及び並列化手法(後述)に応じて、ジョブ設計パターンではtRunJobの親子呼び出しのネストレベルを3つまでとすることをお勧めします。 それ以上ネストしても大丈夫ですが、どのようなユースケースでも、合理的に考えて5つあれば十分に機能します。
tRunJobとジョブレット
子ジョブとジョブレットの違いを簡単に言うと、子ジョブがジョブから「呼び出される」ものであるのに対して、ジョブレットはジョブに「含まれる」ものであることです。 両方とも、再利用可能なコードモジュールや汎用のコードモジュールを作成するために利用できます。 どのジョブ設計パターンにおいても、これらを適切に利用することで、戦略の効果が非常に高くなります。
エントリー/終了ポイント
全てのTalendジョブは、いずれかのポイントで開始し、終了する必要があります。 Talendが提供する2つの基本コンポーネントである tPreJobとtPostJobは、ジョブの内容が実行される前後で何が起こるかを制御することを目的としています。 これらを「初期化」と「まとめ」の手順と考えることができます。 tPreJobが最初に実行された後、実際のコードが実行され、最後にtPostJobコードが実行されるという、期待どおりの動作を行います。 tPostJobコードは、コード本体内に作成された終了ポイント(たとえば、tDieコンポーネント、またはコンポーネントのチェックボックスオプションの「エラー時に終了」)のいずれに遭遇する場合も実行されることに注意してください。
tWarn及びtDieコンポーネントを使用することも、ジョブのエントリー/終了ポイントの考慮事項とする必要があります。 これらのコンポーネントは、ジョブがどこでどのように完了すべきかについてプログラミング可能な制御を提供します。また、エラー処理、ログ管理、及び回復の機会が改善されます。
このジョブ設計パターンでは、コンテキスト変数を初期化し、接続を確立し、重要な情報を記録するためにtPreJobを使用することをお勧めします。tPostJobは、接続を終了したり、その他の重要なクリーンアップや追加のログ管理に使用できます。かなり簡単なことですが、実行していますか。
エラー処理とログ管理
これは重要不可欠であり、共通のジョブ設計パターンを適切に作成すると、ほぼ全てのプロジェクトで再利用性の高いメカニズムを確立できます。一貫性のある維持可能なロギングプロセッサー用に、「logPROCESSING」ジョブレットを作成することで、あらゆるジョブに組み込むことができ、さらに整合性、再利用性、及び高効率を提供する明確に定義された「リターンコード」を組み込むことができます。 これは、記述しやすく、読みやすく、もちろん維持も簡単です。 プロジェクトのジョブ全体でエラーを処理して記録するための「自分なりの方法」を確立できれば、作業負担が大幅に軽減されるはずです。プロジェクトのジョブ全体でエラーを処理して記録するための「自分なりの方法」を確立できれば、作業負担が大幅に軽減されるはずです。
Talendの最近のバージョンでは、Log4jとログサーバーの使用がサポートされるようになっています。 メニューオプションで[Project Settings] > [Log4j]を有効にし、TACでLog Stashサーバーを設定するだけです。この基本機能をジョブに取り入れることは、間違いなくグッドプラクティスです
OnSubJobOK/ERRORとOnComponentOK/ERROR(及びRun If)のコンポーネントリンク
Talendの開発者にとって、「On SubJob」や「On Component」のリンクの違いがわかりにくいことがあります。 「OK」と「ERROR」は明らかです。 では、これらの「トリガー接続」の違いは何であり、ジョブ設計フローにどのように影響するのでしょうか。
コンポーネント間の「トリガー接続」は、サブジョブ内にコンポーネント間の依存関係が存在する場合の処理シーケンスとデータフローを定義します。 サブジョブの特徴は、コンポーネントに現在のデータフローを処理する1つ以上のコンポーネントがリンクされていることです。単一のジョブ内に複数のサブジョブが存在できます。デフォルトでは、関連する全てのサブジョブコンポーネントが、青いボックス(ツールバーでオン/オフの切り替え可能)に囲まれて強調表示されます。
「On Subjob OK/ERROR」トリガーは、サブジョブ内の全てのコンポーネントが処理を完了した後、次の「リンク」されたサブジョブへと処理を継続します。 Tこれは、サブジョブの開始コンポーネントからのみ使用する必要があります。 「On Component OK/ERROR」トリガーは、特定のコンポーネントが処理を完了した後、次の「リンク」されたコンポーネントへと処理を継続します。次の「リンク」されたコンポーネントへのプロセスの継続がプログラミング可能なJava式に基づいている場合に、「Run If」トリガーは非常に便利です。
ジョブループについて
ほぼ全てのジョブ設計パターンで重要となるのは、コード内の「メインループ」と「セカンダリーループ」です。 これらのループは、ジョブの実行の潜在的出口の制御が行われるポイントです。 メインループ」は、一般にデータフロー結果セットの最上位処理であり、これが完了するとジョブは終了します。 「セカンダリーループ」は高次ループ内にネストされ、ジョブの適切な終了を保証するために詳細な制御が必要となることがあります。私は、常に「メインループ」を特定し、tWarn及びtDieコンポーネントを制御コンポーネントに追加するようにしています。 通常、tDieはJVMをすぐに終了するよう設定されます(この場合でもtPostJobコードは実行されます)。 これらの最上位の終了ポイントは、単純な「0」(成功)と「1」(失敗)のリターンコードを使用しますが、確立された「リターンコード」のガイドラインに従うのが最善です。「セカンダリーループ」(及びフロー内のその他の重要コンポーネント)は、追加のtWarnコンポーネントとtDieコンポーネントを組み込むのに最適な場所です(この場合、tDieはJVMを即座に終了するよう設定されません)。
上記で説明したほとんどのジョブ設計パターンのベストプラクティスを、以下の図に示します。 便利なコンポーネントラベルを使用していますが、コンポーネントの配置では若干ルールを変更しています。
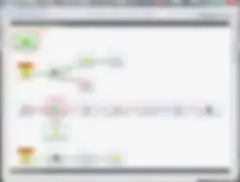
まとめ
ジョブ設計パターンに関する全ての疑問に答えているとは言えませんが、これは第一歩です。 ここでは、いくつかの基本事項を取り上げ、方向性と終盤のヒントを提示しました。
このトピックについて全般的に取り上げるため、別の記事(おそらく何回かに分けて)を書く必要があります。 次回は、いくつかの貴重な高度なトピックと、誰もが何らかの形で遭遇する可能性があるいくつかのユースケースに焦点を当てる予定です。 また、カスタマーサクセスアーキテクチャーチームは、これらのユースケースに対応するサンプルのTalendコードを作成しています。サンプルコードは、Talendヘルプセンターで登録済みのお客様向けに近日中に公開される予定です。どうぞご期待ください。
関連リソース
5 Ways to Become A Data Integration Hero
この記事で取り上げている製品
